人工智能深度學習入門練習之三十四 揭秘多層神經網絡
在人工智能的廣闊天地中,深度學習以其強大的特征學習和模式識別能力,成為推動技術革新的核心引擎。其中,多層神經網絡(又稱深度神經網絡,Deep Neural Networks, DNNs)是構建這一引擎的基石,它模仿人腦神經元的多層連接結構,實現了對復雜數據的高層次抽象和理解。
一、多層神經網絡:從單層到深度的飛躍
早期的感知機模型僅包含輸入層和輸出層,功能單一,無法解決線性不可分問題(如經典的異或問題)。多層神經網絡的引入,在輸入層和輸出層之間加入了一個或多個隱藏層,這帶來了革命性的變化。
- 核心思想:每一層神經元都從前一層接收輸入,通過加權求和并施加非線性激活函數(如Sigmoid、ReLU等),將處理后的結果傳遞給下一層。隱藏層就像一個“黑箱”,自動地從原始數據中逐層提取和組合特征。
- 特征抽象過程:淺層網絡可能學習到邊緣、顏色等基礎特征;隨著層數加深,網絡能夠組合這些基礎特征,形成更復雜的結構,例如在圖像識別中,從邊緣到紋理,再到物體部件,最終識別出完整的物體。
二、多層神經網絡的關鍵組成與工作流程
一個典型的多層神經網絡包含以下幾個關鍵部分和工作流程:
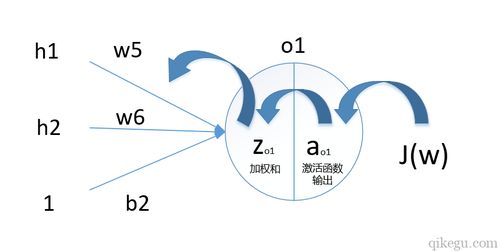
- 前向傳播(Forward Propagation):數據從輸入層開始,逐層經過加權計算和激活函數,最終得到輸出層的預測結果。這是網絡進行“思考”和“推斷”的過程。
- 損失函數(Loss Function):衡量網絡預測輸出與真實標簽之間的差距。常見的損失函數包括均方誤差(用于回歸)和交叉熵損失(用于分類)。
- 反向傳播(Backpropagation):這是多層神經網絡學習的核心算法。它根據損失函數的計算結果,利用鏈式求導法則,將誤差從輸出層向輸入層反向傳播,并計算出網絡中每個參數(權重和偏置)對總誤差的“貢獻度”(梯度)。
- 參數優化(Optimization):利用反向傳播計算出的梯度,通過優化算法(最經典的是梯度下降法及其變種,如隨機梯度下降SGD、Adam等)來更新網絡中的權重和偏置,目標是使損失函數的值最小化,即讓網絡的預測越來越準確。
這個過程(前向傳播 → 計算損失 → 反向傳播 → 更新參數)會迭代進行多次(即多個“訓練輪次”),直到模型性能達到滿意水平或收斂。
三、實踐入門:以“大碼王”為例的軟件開發視角
對于像“大碼王”這樣的人工智能基礎軟件開發平臺或學習者而言,理解和實踐多層神經網絡是構建AI應用的關鍵一步。以下是入門的實踐路徑建議:
- 夯實數學與編程基礎:理解反向傳播和優化算法需要一定的線性代數、微積分和概率論知識。熟練掌握Python是進入AI開發領域的敲門磚。
- 選擇高效開發框架:無需從零開始編寫復雜的矩陣運算和求導代碼。應充分利用成熟的深度學習框架,如:
- TensorFlow / Keras:工業級框架,生態龐大,適合部署。Keras API尤其對新手友好。
* PyTorch:以動態計算圖和直觀的編程風格深受研究人員喜愛,靈活性極高。
“大碼王”平臺若旨在教育或快速原型開發,集成或借鑒這些框架的簡潔API設計將極大降低學習門檻。
- 從經典項目開始動手:
- 手寫數字識別(MNIST):使用包含1個或多個隱藏層的全連接網絡,這是深度學習的“Hello World”。
- 簡單圖像分類(CIFAR-10):挑戰稍大的數據集,可以嘗試結合卷積神經網絡(CNN,一種特殊的用于圖像的多層網絡)。
- 情感分析或文本分類:使用循環神經網絡(RNN)或其變體處理序列數據。
- 理解并調試模型:在軟件開發中,調試至關重要。要學會:
- 使用工具(如TensorBoard)可視化訓練過程中的損失和準確率曲線。
- 分析過擬合與欠擬合,并應用如丟棄法(Dropout)、正則化等技術來改善模型泛化能力。
- 調整超參數(如學習率、網絡層數、每層神經元數量等),這是優化模型性能的“藝術”。
四、與展望
多層神經網絡是深度學習大廈的根基。它通過增加模型的深度和復雜度,賦予了機器前所未有的學習和表示能力。對于軟件開發者和學習者(“大碼王”)來說,掌握其原理并付諸實踐,是開啟人工智能應用開發大門的鑰匙。從理解前向/反向傳播的基本原理,到利用現代框架實現第一個能運行的網絡,再到不斷調優解決實際問題,每一步都是積累和成長。
盡管更復雜的結構(如Transformer)在特定領域大放異彩,但多層神經網絡的基本思想和訓練范式仍然是整個領域的通用語言。深入理解它,將為探索更前沿的AI模型奠定堅實的基礎。
如若轉載,請注明出處:http://www.xyhm.com.cn/product/80.html
更新時間:2026-03-03 08:37:10